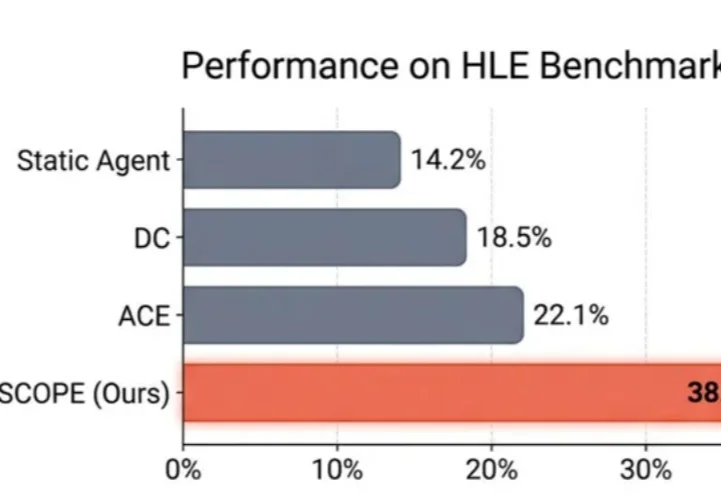
Agent「记吃不记打」?华为诺亚&港中文发布SCOPE:Prompt自我进化,让HLE成功率翻倍
Agent「记吃不记打」?华为诺亚&港中文发布SCOPE:Prompt自我进化,让HLE成功率翻倍在 LLM Agent 领域,有一个常见的问题:Agent 明明 "看到了" 错误信息,却总是重蹈覆辙。
来自主题: AI技术研报
8739 点击 2025-12-30 09:54
 搜索
搜索
在 LLM Agent 领域,有一个常见的问题:Agent 明明 "看到了" 错误信息,却总是重蹈覆辙。

在代码大模型(Code LLMs)的预训练中,行业内长期存在一种惯性思维,即把所有编程语言的代码都视为同质化的文本数据,主要关注数据总量的堆叠。然而,现代软件开发本质上是多语言混合的,不同语言的语法特性、语料规模和应用场景差异巨大。
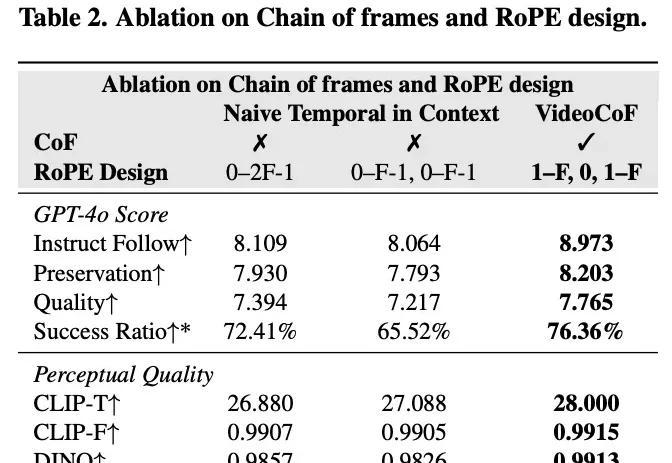
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!
2025年12月12日,波士顿大学的 Andrey Fradkin 团队发布了一项令业界瞩目的研究 《The Emerging Market for Intelligence: Pricing, Supply, and Demand for LLMs》(智能的新兴市场:LLM的定价、供给与需求)。

扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。然而在 Any-order 解码模式下,其通常面临
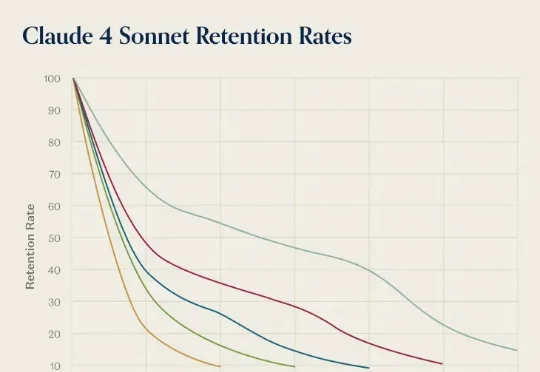
前几天,AI 推理服务供应商 OpenRouter 发布了一份报告《State of AI》,基于平台上 60 多家提供商的 300 多个模型,100 万亿个 token 的交互数据,对 LLM 的实际应用情况进行了分析。报告中,提到了一个「灰姑娘水晶鞋效应」,特别有意思。研究者在分析用户留用数据时发现一个现象:AI 模型发布第一个月进来的用户,往往比后来进来的用户留存率更高。
今年 10 月,专注构建世界模型的 General Intuition 完成了高达 1.34 亿美元的种子轮融资。这笔融资由硅谷传奇投资人 Vinod Khosla 领投,这是他自 2019 年首次投资 OpenAI 以来开出的最大单笔种子轮投资,也标志着他在 LLM 之后对下一代智能范式做出的一次重大下注。
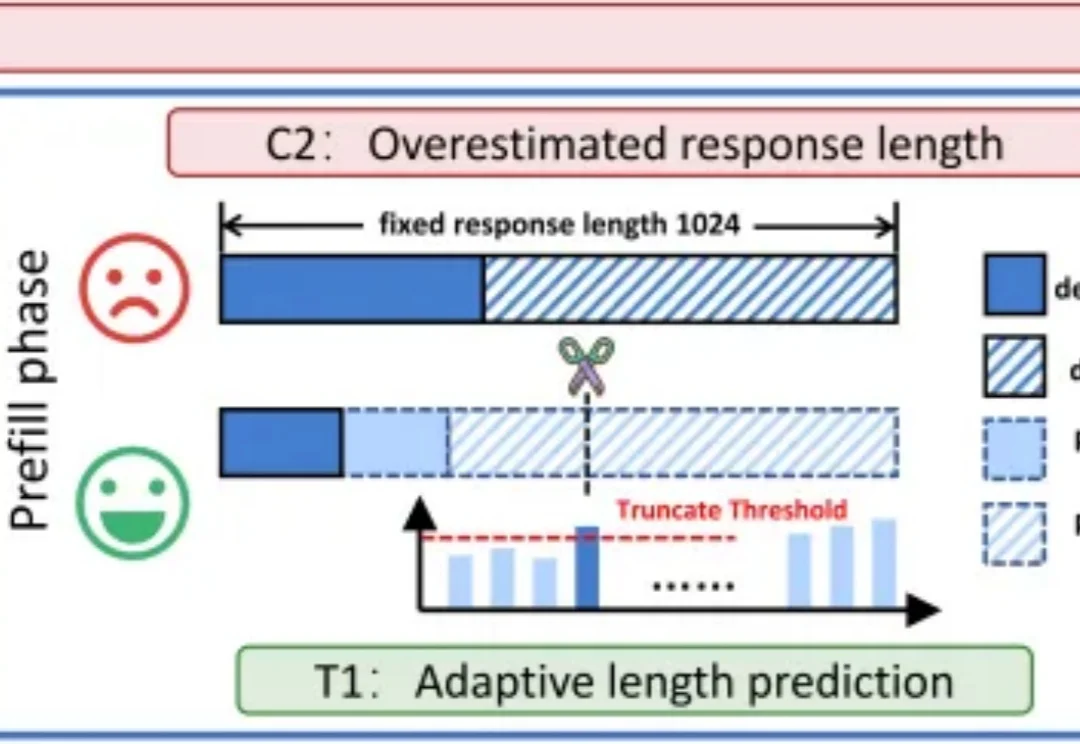
基于扩散的大语言模型 (dLLM) 凭借全局解码和双向注意力机制解锁了原生的并行解码和受控生成的潜力,最近吸引了广泛的关注。例如 Fast-dLLM 的现有推理框架通过分块半自回归解码进一步实现了 dLLM 对 KV cache 的支持,挑战了传统自回归 LLMs 的统治地位。
一直以来,传统 MAS 依赖自然语言沟通,各个 LLM 之间用文本交流思路。这种方法虽然可解释,但冗长、低效、信息易丢失。LatentMAS 则让智能体直接交换内部的隐藏层表示与 KV-cache 工作记忆,做到了:
这篇学术论长文由北京航空航天大学复杂关键软件环境全国重点实验室领衔。《From Code Foundation Models to Agents and Applications》一文是对过去几年代码智能领域的一次系统梳理:模型、任务、训练、智能体、安全与应用都被串联成了一条完整、连贯的技术链路。